







Zero Trust architecture (ZTA) implementations rely on many components that integrate with each of the Zero Trust model’s pillars and must work seamlessly to drive the best decision-making in the policy engine (PE) and trust algorithm components. The trust algorithm is one of the more complex and core components to implement in any ZTA environment, especially across large and diverse networks.
This algorithm continuously ingests voluminous amounts of data (network traffic metadata, application metadata, endpoint metadata, security event log data, and so on) and assigns risk to each account and device to render access decisions. The trust algorithm includes an artificial intelligence (AI)/machine learning (ML) algorithm that helps compute risks and enable faster and more accurate decisions. Machine learning is a subset of AI.
The National Institute of Standards and Technology (NIST) defines AI as:
- A branch of computer science devoted to developing data processing systems that perform functions normally associated with human intelligence, such as reasoning, learning, and self-improvement.
- The capability of a device to perform functions that are normally associated with human intelligence such as reasoning, learning, and self-improvement.
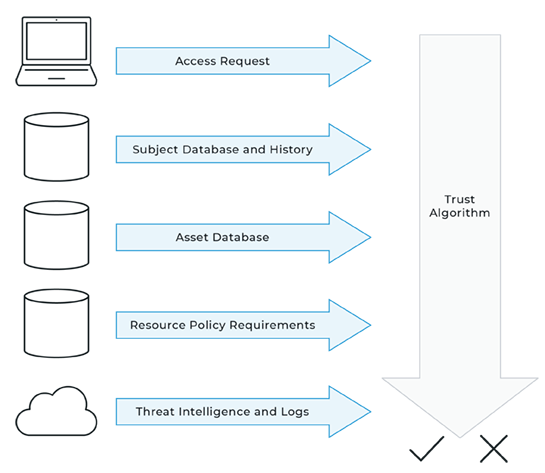
Trust algorithm as defined by NIST SP 800-207: For an enterprise with a ZTA deployment, the policy engine can be thought of as the brain and the PE’s trust algorithm as its primary thought process. The trust algorithm (TA) is the process used by the policy engine to ultimately grant or deny access to a resource. The policy engine takes input from multiple sources (see Section 3): the policy database with observable information about subjects, subject attributes and roles, historical subject behavior patterns, threat intelligence sources, and other metadata sources.
The first step of any AI/ML endeavor is to identify and collect data from various data sources within the ecosystem so you have sufficient visibility across network, data, endpoint, user, device, and application pillars. The next step is to perform data preparation, which includes data normalization, followed by developing and testing the model. Data collection and preparation are crucial to the accuracy and success of your AI base for the trust algorithm. It is important to note that the AI/ML being discussed is designed for analysis and classification of data to make decisions; it is not what has widely been called generative AI, which uses AI to create novel content such as text or audio.
Data normalization is the practice of organizing data entries to ensure they are consistent across all fields and records. Data normalization becomes more important when your trust algorithm assigns a trust score based on the analysis of data across numerous heterogeneous environments, including multiple cloud service providers, legacy systems, and on-premises computing across physical, virtual, and container resources.
This is where things get interesting and more complicated. Applying AI/ML models to different kinds and sources of data sets to compute risk scores for the trust algorithm becomes challenging because the data is not normalized. It becomes difficult and ineffective to train AI/ML models across different data sets because the model would not see the apples-to-apples comparison; it would likely see it as apples to cucumbers. Data normalization enables standardization and consistent data so you can train and build effective AI/ML models to make sound risk decisions.
It’s one thing to generate metadata and create and train AI/ML models when they are sourced from one cloud service provider where all metadata is standardized and consistent. In this case, the AI/ML process to train classifiers will clearly be easier and likely more accurate than it would be when ingesting data from various cloud service providers and on-premises networks where the data is inconsistent. That added complexity, even when normalized, will make the AI/ML training more challenging and thus lead to lesser performance and accuracy.
Ideally, one approach would be to have a single solution create and standardize metadata across network traffic from all environments (on-premises, software-defined networks, containers, and cloud workloads across multiple cloud service providers). This will reduce complexity and the burden on the organization to prepare and normalize the metadata used to build an effective and reliable AI/ML-based trust algorithm to support its Zero Trust architecture.
Gigamon Application Metadata Intelligence (AMI), running on either the GigaVUE® HC Series of physical appliances or GigaVUE V Series of public or private cloud appliances, can generate standardized metadata across physical, virtual, and cloud infrastructure.
Fundamentally, the value of Gigamon is giving you visibility of the network. It doesn’t matter which part of the hybrid multi-cloud network you need: on-prem, data center, regional, tactical, mobile, industrial, public cloud, or private cloud — Gigamon can provide. But access is only one aspect that is needed: Tools need the ability to efficiently process the captured traffic, and this avoidance of normalization is key to making threat detection powerful and efficient, especially when using AI/ML to make decisions.
The ability to observe your environments through the same lens is critical: Attackers won’t respect your cloud infrastructure simply because you see it some different way. Bring in Gigamon, and let us show you the power of viewing your hybrid multi-cloud infrastructure through one lens and leaving attackers no place to hide.
Featured Webinars
Hear from our experts on the latest trends and best practices to optimize your network visibility and analysis.

CONTINUE THE DISCUSSION
People are talking about this in the Gigamon Community’s Security group.
Share your thoughts today