







Detection engineers design and build security systems that constantly evolve to defend against current threats. Two common defenses include securing networks via configuration changes (GPO, basic firewalls, etc.) and deploying active prevention security suites (advanced firewalls, antivirus, etc.). Because security professionals recognize that no system can perfectly keep out attackers, the other option is to detect malicious behaviors – in network traffic and/or on a host – that bypassed the other security controls. The category of products that detect (and optionally respond to) threats is primarily known as Endpoint Detection and Response (EDR) for endpoints and Network Detection and Response (NDR) for network traffic. We’re going to focus this blog on things that detection engineers should keep in mind while producing detection content for malicious activity that bypasses security controls from a network perspective.
As there are lots of facets to detection engineering, I want to be upfront about what this blog won’t cover. We won’t talk about measuring detection coverage or prioritizing research. We won’t have time to dig into building detection content across the spectrum of behaviors and we won’t be able to talk about quality assurance for detection content. Some of those topics are planned for future posts, so stay tuned. This particular blog will stick to the basics by addressing what a detection rule consists of and some common issues you may encounter as you start building detection content. This diagram shows, at a high level, some relevant topics to Detection Engineering, and approximately how they relate to each other, and highlights what we’ll be focusing on for this blog.
Goal for Detection System
When building a solid detection system, your primary goal is to catch bad things and to not catch too many not bad things. If you interrupt an analyst’s workflow (or your own) to call attention to things that are not bad, then you’re creating more work – and potentially resentment. Detection products only create value by detecting things that are truly bad, and most detection products lean towards detecting more activity so as to not miss anything (prioritizing low false negatives). This is because, for non-preventative detection products (i.e., those that do not block activity), the cost of incorrectly detecting benign activity is perceived to be very low.
The truth is, turning that knob for more detections causes a higher false positive rate and irrelevant alerts that distract analysts. Alert fatigue is real and results in analysts ignoring expensive security products. So how exactly do we write rules to catch mostly only bad things while ignoring most of the not bad, since that is likely the bulk of what is occurring in your networks?
Hypotheses Focus Security Efforts
As detection engineers, we apply the study of adversary behaviors to the identification of malicious behaviors. We have limited time to research and create detections, so we use assessed levels of generic threat coverage and intelligence driven priorities for specific threats to focus our efforts. In a previous role, I hunted for adversaries in customer networks. A key part of our methodology included generating a series of hypotheses – informed by my past as an attacker – about what an adversary could be doing on the network. As I performed a “threat hunt” I tested each hypothesis by gathering data and checking to see if it was correct. When the data confirmed my hypothesis, I took the next step to isolate the known threat; when the data contradicted my idea of what was happening, I modified the hypothesis and gathered more data. Oftentimes, my investigation didn’t turn up any malicious behavior, and I didn’t always know if this was due to an incorrect hypothesis about adversary behavior or simply because that activity was not present in the specific data I was examining. The iterative process of creating a hypothesis, gathering data, and analyzing the results allowed me to quickly identify the specific malicious activity on the network.
The follow-up to successful identification of malicious behaviors involves automation. I would implement a script or write a query to automatically “hunt” for and notify me of future malicious behaviors similar to those discovered in my manual threat hunt. This is an important initial activity in detection content development.
What Is a Detection?
Now that we know how to begin developing detection content, let’s define what makes up a detection. A detection is made up of a subject, a method, and other attributes. The subject is what we are trying to detect. If my goal is to identify a piece of malware, then the malware is the subject. Alternatively, a behavior could be the subject. The method covers how I identify the subject. For example, I may consider high counts of subdomains for newly created second–level domains (2LDs) to be an indication of Domain Name Service (DNS) Command and Control (C2). The method is examining counts, while the subject is DNS C2. Finally, detections include other attributes (metadata) to add meaning to the detection. For example, I may map the detection rule to MITRE ATT&CK™ or some other taxonomy to provide context. I will probably assign the rule a severity score (the damage that can by caused if the observed action succeeds) and a confidence value (how well the rule identifies the behavior).
Important caveat on confidence: in this industry “confidence” often means different things to different people. We find it helpful to be more specific when writing detection rules about what confidence means to us. In fact, in addition to our confidence that the rule logic will identify the named behavior (this can be more accurately labeled as rule performance), we also track threat confidence, which aligns to how well we expect a rule to find malicious behaviors. This is best illustrated by looking at a generic rule attempting to catch a specific TTP. For example, if I write a rule intending to catch executables being served from the root directory of a web server, it is likely that my rule logic will perform at a high level. In other words, I should have high confidence that any matched traffic will be associated with this action. However, I am less likely to be confident in that rule’s ability to catch malicious downloads, since there are some legitimate services that serve executables from the root directory over HTTP (shame on you). The rule performance may be high, but the threat confidence will likely be low.
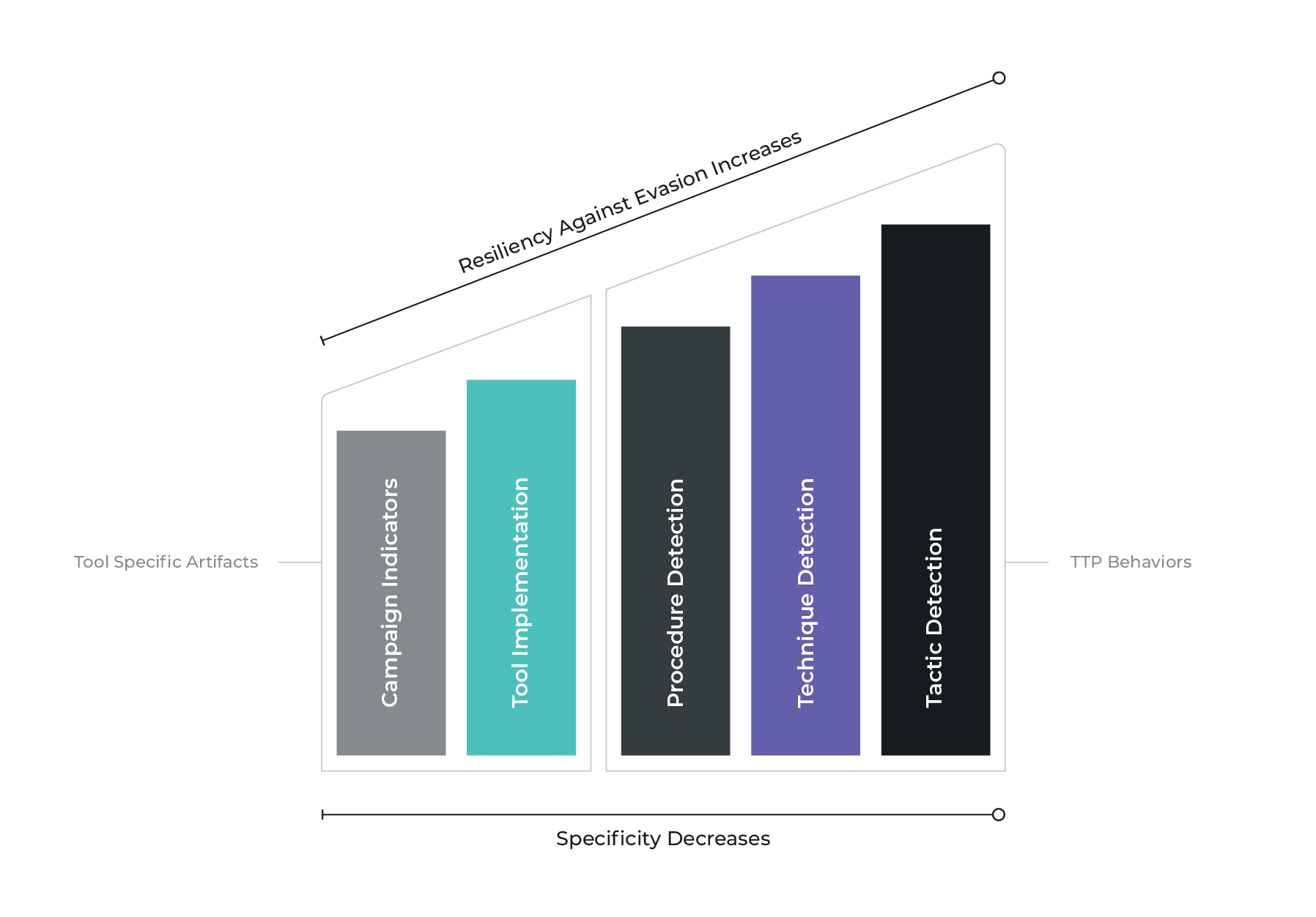
Finally, an important metric to maintain is the specificity of the subject. How does the subject get classified in terms of generic-ness? In other words, where am I aiming with respect to the Pyramid of Pain? If you’re not familiar with the Pyramid of Pain, please read the excellent blog post by David Bianco explaining his creation. If I take aim at the top of the pyramid and target a non-tool specific TTP, I may have less confidence that every detection match corresponds to malicious activity. However, the benefit of such a generic TTP-based rule is that the one detection can identify the activity of every malicious tool that employs the TTP. For example, I cannot expect to find Cobalt Strike’s Beacon DNS C2 with a DNS C2 rule written to look specifically for dnscat2. On the flip side, a more generic rule may do a great job of detecting many different variants of tools utilizing DNS for C2, while at the same time have an increased rate of false positives.
For our purposes we have chosen to assign our detection rules to one of 5 categories. Campaign represents those detections reliant on observable indicators that change frequently, like IP addresses or domain names. Tool Implementation detections are associated with observable attributes of specific tools. These observable attributes are often easily changed in source code, but rarely are in practice. User Agent strings and SSL subject/issuer patterns are some common examples. Next are Procedure, Technique, and Tactic-level detections. These map roughly to the MITRE ATT&CK™ definitions. If you’re unfamiliar with their usage, see their product documenting the design and philosophy behind MITRE ATT&CK™. When we write detection content our aim is to produce rules that target various levels of the Detection Specificity Spectrum for increased resilience. If a campaign-level detection catches threat activity, that’s great. Even better if you have multiple overlapping detection rules firing on the same activity because they target various levels of specificity.
Detection specificity can also play a critical role in measuring coverage and prioritizing future detection gaps by being more clear what quality of coverage you have, just not that you have coverage. There is much more to say on this subject, so perhaps we’ll go more in depth in a future blog post. Additionally, go read the excellent articles written by Jared Atkinson of SpecterOps titled Capability Abstraction and Detection Spectrum, which quite clearly shows the various levels of specificity that a detection rule can target.
Clearly articulating the subject, method, and associated metadata helps the security analysts who review the detection hits and the detection engineers responsible for measuring how well existing detections cover all attacker tools and techniques.
When Detections Break You
The next section highlights complexities that can plague detection engineers: differences between networks, invalid assumptions, and the good idea fairy. You’ll come face to face with each of these issues as you develop detection content for your organization.
Variance Between Subnets/organizations
Detection engineers must be vigilant to identify areas where a well-performing detection rule in one network fails to produce the desired results in another – especially when creating detections that are used across several organizations (internal or external). Group A may commonly utilize a specific software package that Group B deems a security finding. For example, the research team may use the same remote desktop software employed by malicious actors to control networks. Detecting its use may effectively highlight illicit activity in one part of the network, and yet, in another, it may just add unnecessary noise that does not help a defender to find malicious behaviors.
Bad Assumptions
As we’ve said previously, during a threat hunt, a common tactic is to hypothesize what you will find and then search for data that confirms or denies this hypothesis. For example, I may look for PowerShell.exe making network connections outbound to virtual private servers based on my understanding of attacker behavior. If all outbound PowerShell connections that I find during this one-time hunt are malicious, I may assume all such activity is bad and craft a detection rule to notify me about all instances of PowerShell downloading files from VPS ASNs. The analyst monitoring the outputs from this detection rule will curse me when a system administrator legitimately uses PowerShell to download a PE file from an obscure software company hosted at DigitalOcean.
Easy Mode Isn’t Always Easy
Sometimes I may analyze a piece of malware, notice a statically configured SSL certificate and think I’ll be able to detect this malware with relative ease. Problems arise when the SSL certificate matches a pattern used by legitimate applications. Here’s a great idea I’ve heard many times: You can find malware by looking for ‘beaconing’ activity. You know, look for consistent connections between hosts at some interval. Before someone has put in the work to determine if this actually works, they have an epiphany and run with it. You’ll be able to detect so much malware this way, they say. Yes, you certainly can, if you can weed through all the other (non-malware) nonsense first. Oftentimes something that seems like a slam dunk will not bear fruit, and it may require lots of tuning and/or additional filtering to become effective.
Case Study
To showcase a real example of malware that puts up a (small) fight, let’s take a look at a detection rule that our team recently authored. After weighing our detection priorities, we decided to look at the open source RAT known as pupy. We downloaded a malware sample, generated an agent, and connected this agent back to a server while monitoring the network traffic.
We analyzed the collected data to figure out one or more rules that uniquely identify pupy activity. The pupy agent uses HTTP for C2, and the user agent is hardcoded into the source code. That should be an easy win, right? Unfortunately, this user agent also appeared intermittently in traffic we confirmed to be created by a legitimate application – in this case, Google Chrome. The attribute we presumed to be unique is not, so we’ll have to find additional statements to add to our query. Our “easy win” turned out to require a bit more effort.
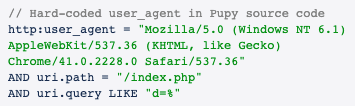
After more observation, rule writing, and testing, we identified unique observable attributes and confirmed that – in combination – they uniquely* describe the malicious pupy sample. At this point we assign specificity, confidence, severity, and MITRE ATT&CK™ technique(s) as additional attributes to this detection rule.
* Based on the data currently available.

Summary
In this blog we discussed the goals, overall approach, and some of the headaches of creating meaningful detections as part of a holistic security system. Each individual detection rule is the logic that detects (hopefully) malicious activity on the network you’re defending. Your own prioritization determines which detection rule to create next. Testing the logic against available data reveals additional attributes of each detection, such as its accuracy, specificity vs. resilience, and applicability across networks. Iterating this creative process eventually will result in a comprehensive suite of detection content ready to notify you of badness when an attacker bypasses the security system’s other controls.
What’s Next
A robust testing regimen is crucial to maintaining a resilient, reliable detection system. Unfortunately, it seems to be the case that once put into production, detection content is often left to die. If one does not continue to monitor the quality of their detection content over time, how will the accuracy and reliability be assessed in the midst of a changing landscape? Short answer: if you don’t test it, you can’t trust it. And if you can’t trust your content, then why should your analysts trust you?
Join us next time as we dive into quality control (QC) processes that continually assess detection content.
Read part 2: Quality Control: Keeping Your Detections Fresh