








What Is Network Management?
The International Organization for Standardization (ISO) identifies five essential areas of network management: Fault, Configuration, Accounting, Performance, and Security (FCAPS).
Fault and configuration management
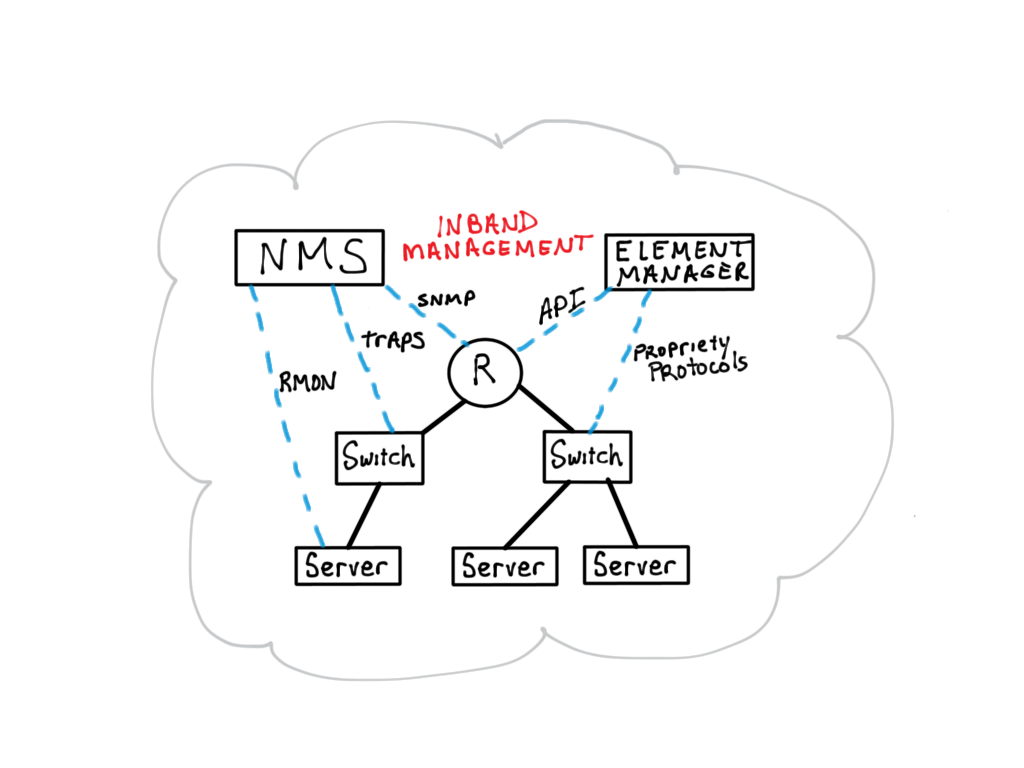
In my experience, the easier FCAPS components to implement are fault and configuration. Both are typically done using an in-band solution that engages the devices that run your network.
Fault management is often initiated at the management system using ICMP pings and SNMP, and may also include information pushed from the network devices using Syslog and SNMP Traps. The goal is to detect faults as they occur and initiate a manual or automated correction.
Security management
Security is the next most commonly implemented network management function and can be viewed as two parts: one is to ensure the security of the network devices; the other is to ensure the security of the computing environment.
Securing network devices is relatively straightforward. You apply firmware patches on a regular basis and centrally control access to the devices using RADIUS or TACACS+. These two services provide authentication (controlled access to the network device); authorization (defines what a particular user can do on the network device); and accounting (keeps track of the changes a particular user makes to the network device).
Securing the overall computing environment, by contrast, is more complex. Today, there are numerous tools available for monitoring the computing environment to detect malicious activity that seeks to disrupt network operations, steal information, or control systems. Increasingly, more and more tools are being developed to prevent such malicious activity from starting in the first place. These tools are deployed within the network and may collect information from the devices that manage the network. However, to provide a complete security analysis, they also require visibility into the traffic traversing the network.
Performance management
The final area is performance management. While easy to understand, it is difficult to do. Over the last 15 years, many products have been developed to help network managers identify when the network is struggling to perform at an acceptable level. Regardless of the varied root causes of a performance issue, the impact to the end users is real.
Early knowledge of performance issues within a computing environment can allow network managers to be pro-active in solving minor issues before they become major. The devices that run the network provide critical information on their health; this information is typically collected in-band directly from the network devices themselves via SNMP or a proprietary API. Unfortunately, this data is not enough to provide an accurate, complete picture of the performance of the network or its applications. While there are a large number of software vendors who have developed solutions to monitor the overall performance of the network and/or the critical applications running in the network, these tools almost always rely on an examination of the packets traversing the network to provide the best possible analysis.
The challenge for security and performance monitoring of the computing environment is how to provide these tools visibility across all the areas of the network that need to be monitored. Traditionally, these tools have been deployed either inline in protect mode at the Internet connection or out of band in monitor-only mode, in which case they are connected to a SPAN port on a switch or router. We will talk more about the best ways to gain visibility into the network packets in the “Sources of Traffic” article that will appear later in this series.
The Next Step in Network Management: Traffic Visibility Platforms
Device-based management is no longer sufficient. The next generation of performance and security tools require visibility into the packets passing through the network.
Enter Traffic Visibility Platforms.
A Traffic Visibility Platform provides the means to aggregate all sources of network traffic (inline bypass, SPANs, TAPs, virtual); send the right data to the right tool through filtering; clean up the data streams by transforming the packet flows; and, lastly, send the data to all the tools or tool groups that need to see those packets.
Gone are the days of running out of SPAN ports. Gone are the days of having to upgrade tools to faster network interfaces because of a network upgrade. Gone are the days of overloading an analysis tool because it had to receive unfiltered, duplicate packets.
Instead, we welcome the world of Traffic Visibility Platforms.
And with Gigamon’s Traffic Visibility Platform, you have endless possibilities. You control which packets you send to your tools. You control which packets or flows get dropped. And you control when you replace your tools to accommodate the growth in network traffic that needs to be analyzed.
